算法学习的笔记1,关于对象数组的一个工具类。
该工具类可实现以下功能:
获取数组的长度
在数组的末尾添加一个元素
打印所有元素到控制台
删除数组中的某个元素
获取某个元素
在指定位置插入一个元素
替换指定位置的元素
工具类代码如下:
1 | package class3_array.utils; |
测试类代码如下:
1 | package class3_array; |
希望能对您有所帮助。
欢迎大家访问我的个人博客

算法学习的笔记1,关于对象数组的一个工具类。
该工具类可实现以下功能:
获取数组的长度
在数组的末尾添加一个元素
打印所有元素到控制台
删除数组中的某个元素
获取某个元素
在指定位置插入一个元素
替换指定位置的元素
工具类代码如下:
1 | package class3_array.utils; |
测试类代码如下:
1 | package class3_array; |
希望能对您有所帮助。
欢迎大家访问我的个人博客
FPGA的课程的大作业,我们选的是数字频率计设计。下面分享一下代码,还有工程文件,还有自己写的论文(里面会有更加详细的介绍),希望可以对你有所启发。
开发环境:Vivado 2015.4+Modelsim(仅用于仿真波形)
开发板:赛灵思公司 xc7a100tcsg324-1
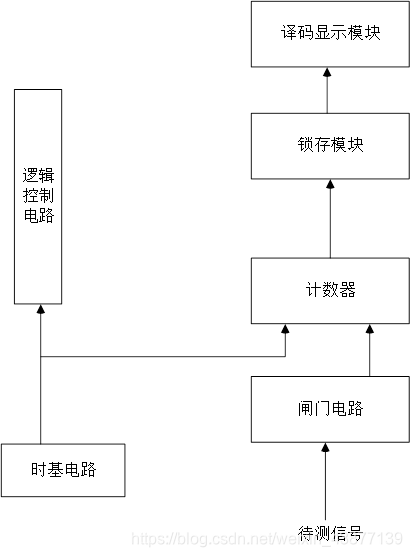
结构图: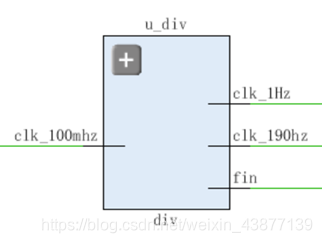 代码如下:
代码如下:
1 | module div( |
被测频率本来要求是学号*1000Hz,但是我的学号无法被整除,所以无法度量频率计的的精度,更无法进行误差分析。所以才选取了100KHz作为测试频率。
结构图:
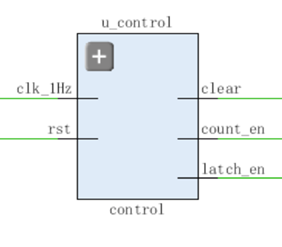
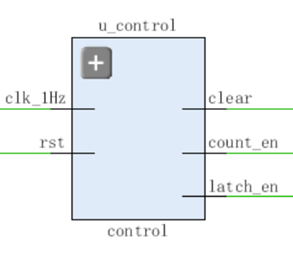
code:
1 | module control(clk_1Hz, rst, count_en, latch_en, clear); |
1 | endmodule |
结构图:
code:
1 | module counter_10(en_in, rst, clear, fin, en_out, q); |
结构图: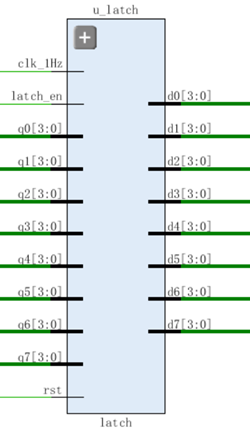
code:
1 | module latch(clk_1Hz, latch_en, rst, q0, q1, q2, q3, q4, q5, q6, q7, |
结构图: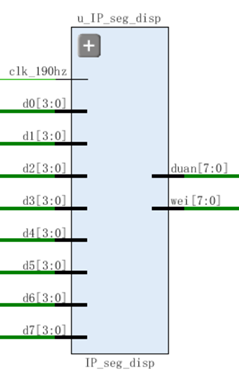
code:
1 | module IP_seg_disp( |
code:
1 | module freDetect(clk_100mhz,rst,duan,wei); |
1 | module freDetect_tb; |
波形仿真结果如图所示: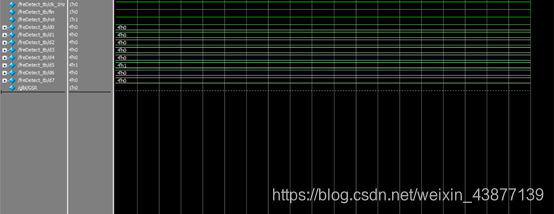
实验结果:
两张图片分别为 测量计数时和复位时和显示计数时:

我也写了几篇关于Veirlog的文章,感兴趣的同学可以去看看。该模块链接如下:
Verilog学习
实现功能:在开发板的数码管上显示特定数字,并且让这些数字循环移位。
总体框图如下: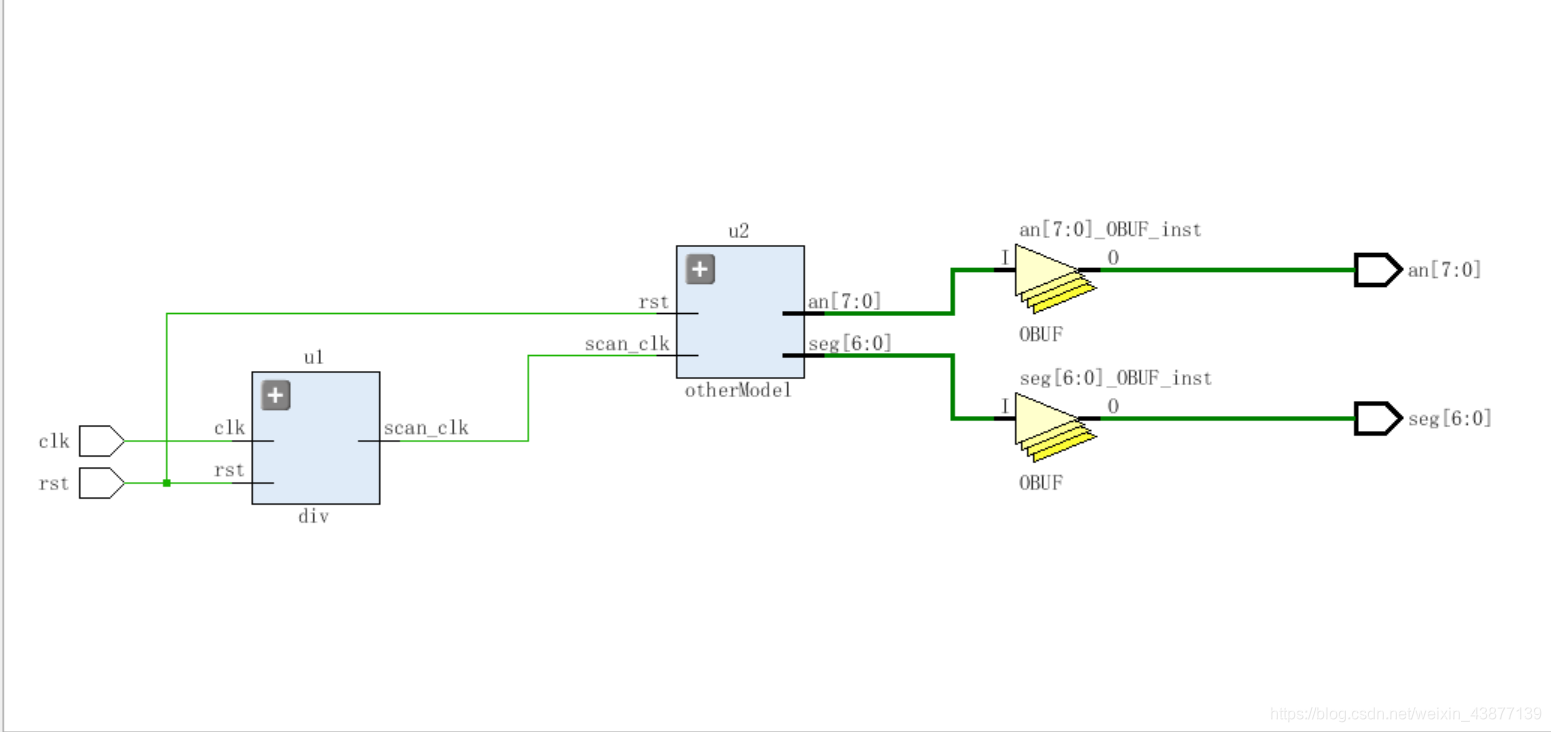
代码如下:
分频模块:
1 | module div( |
其他模块(显示模块):
1 | module otherModel( |
顶层模块:
1 | module top( |
测试文件:
注意:测试文件是针对otherModel文件的。在写测试文件之前,最好不要添加顶层模块,否则测试时会找不到想要测试的那个文件。如果,已经编写完了顶层模块,可以在design列表中,右键要测试的文件,然后点击 设置为顶层文件,这样就会测试到指定的文件了。
1 | module otherModel_tb(); |
仿真波形如下: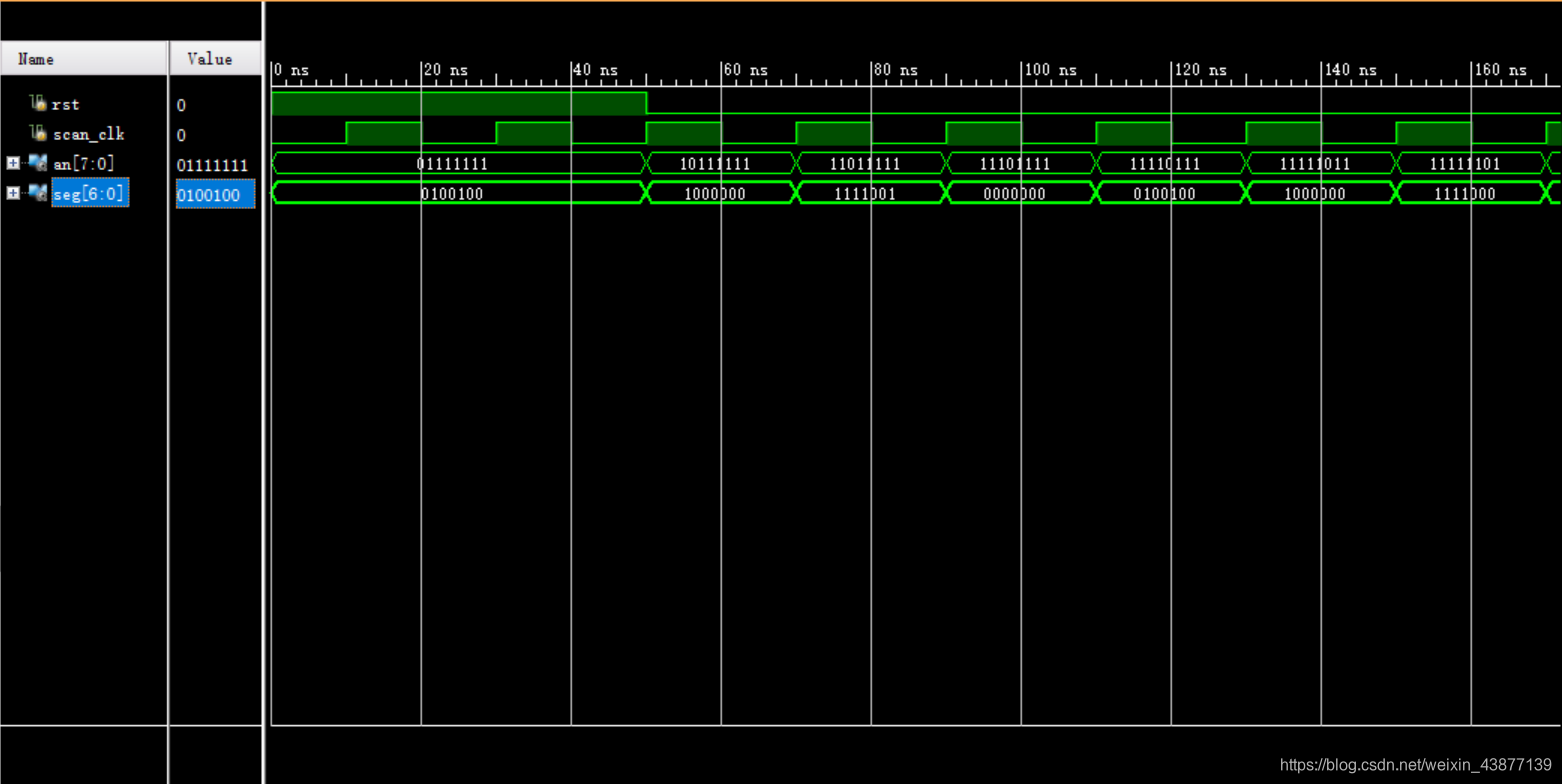
我也写了几篇关于Veirlog的文章,感兴趣的同学可以去看看。该模块链接如下:
Verilog学习
更新:
有同学反馈说:网络效率的函数可能有点问题。可以试试这个网络效率函数,对应的部分改一下就可以了。
还有最大连通子图比例函数:最大连通子图比例函数
上一篇介绍了随机攻击网络节点与蓄意攻击节点的基本方法。上一篇文章地址:matlab实现随机攻击网络节点+蓄意攻击网络节点(1)
其中随机攻击的部分还有一些瑕疵,就是在实际的研究中,需要对网络进行多次(数十次甚至上百次)攻击后取指标变化平均值,这样的实验数据才具有一定的说服力。
其实这个问题乍一听起来,原理也比较简单:就是让一个程序运行指定的次数然后,累加程序中某一个变量后取平均值。
实现起来也并不费劲,首先就是把这个程序定义为一个函数,然后把所需要累加的变量作为函数的返回值。然后在另一个文件中创建循环,在循环中调用该函数,用一个变量接收该函数的返回值,以达到累加的效果,最后在循环外部取一个平均值即可。
代码如下所示:
定义函数文件名称(该名称需要与函数名称相同)
函数的参数介绍:
输入值: str:意为数据文件的路径;numDelete:删除节点的个数(这里的命名只是为了方便并不是必选项)
返回值:Eglob,即网络效率值的数组
1 | function Eglob = ATestAver(str,numDelete) |
定义测试文件:
文件中需要定义随机攻击的次数和随机攻击节点的个数,具体参数设置应视具体网络而定。
在调用函数时,要传入文件路径,和删除节点的个数。
1 | %定义随机攻击节点的个数,具体数值根据网络规模拟定 |
我的测试数据具有小世界特性与无标度特性。并得到了以下的结果: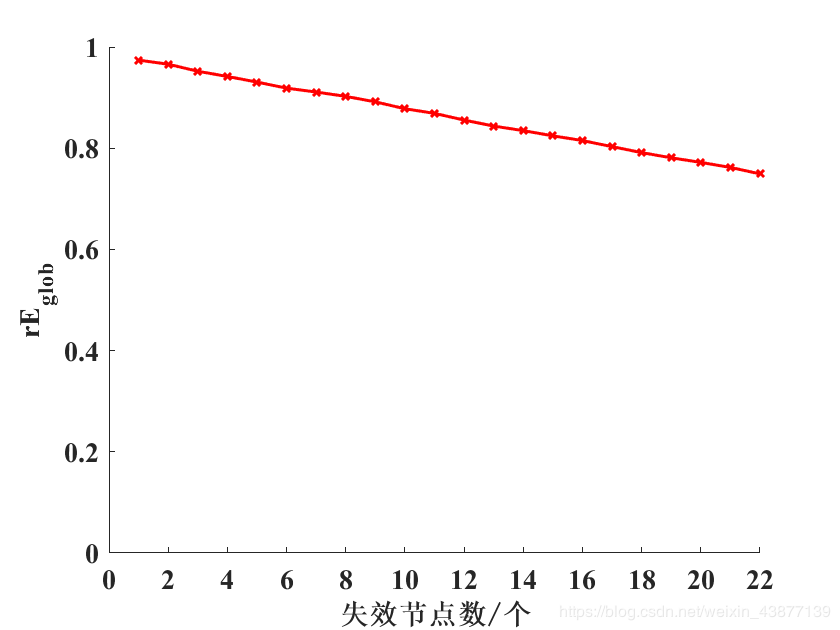
大家可以看出,经过多次随机攻击取指标平均值之后,曲线近似于一条直线,下降速率较小且符合实际的网络情况。验证了无标度网络对于随机攻击拥有较好的鲁棒性。
希望本文对大家有所帮助,有任何问题或者是建议,欢迎大家与我交流。
更新:
有同学反馈说:网络效率的函数可能有点问题。可以试试这个网络效率函数,对应的部分改一下就可以了。
还有最大连通子图比例函数:最大连通子图比例函数
在研究网络的鲁棒性的时候,我们往往会通过随机与蓄意攻击网络节点,观察网络效率的下降比例来进行网络特性的研究。
常见的指标有:最大连通子图比例、网络效率、平均距离等等。
这三个指标是不同的,但是实现随机攻击与蓄意攻击的原理是相同的,这里以按照节点度攻击的网络效率变化为例(其他两个指标就是函数不同,想按照其他节点重要度排序指标,也是类似的,只需要按照想要的排序方法得出节点的排序即可)。
就是按照节点的重要性排序,通过循环来删除节点。把临界矩阵中节点对应的行和列先置0,然后再删除。每删除一次节点,就生成了一个新的邻接矩阵,然后每一次都通过testEglob函数计算出当前的网络效率值。
首先需要准备的数据如下:
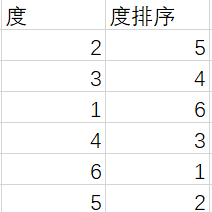
网络的邻接矩阵,节点度的排序(从大到小排名,度大的排名靠前)。
节点度的排名要按照节点的编号排序,下图是一个简单的例子,建议先在Excel中排列好了,然后再复制到Matlab中转置一下保存为mat文件就可以了。
明白了蓄意攻击的原理,那么随机攻击的原理也比较好理解了,蓄意攻击是按照节点重要度排序进行的攻击,那么随机攻击可以理解为给所有节点随机赋排名,所以攻击的时候就等效于随机攻击了。也就是说,在随机攻击时,你只需要在蓄意攻击的基础上添加一行代码,把度排序的数组赋值上长度相同的一个随机数组,即:
1 | Name_Struct.Node_Key_Degree = randperm(440); |
具体代码如下:
主函数: testRandom(命名随意。。。)
作用:原理挺简单的,就是通过循环来删除节点。把临界矩阵中节点对应的行和列先置0,然后再删除。每删除一次节点,就生成了一个新的邻接矩阵,然后每一次都通过testEglob函数计算出当前的网络效率值。
部分代码如下:
1 | % 蓄意攻击:按照节点重要性顺序,一次攻击一个节点 |
正常情况下,一次随机攻击并不能说明什么,一次随机攻击的数据也并不可靠,所以需要多次随机攻击之后取平均值,这样得出的数据才更具有说服力,下一篇将介绍如何实现,matlab实现随机攻击网络节点+蓄意攻击网络节点(2)
本篇文章对应的GitHub工程地址如下:内含函数文件+测试文件,下载即可直接运行。
希望对大家有所帮助,有任何疑问欢迎与我交流,谢谢你的时间。
前三篇文章都是单一模块的设计,然后测试是否来完成特定的功能,不过这种方法只能解决一些简单的问题,所以实际中需要层次花的设计。
这次给大家分享的就是一个层次化的设计,移位寄存器模块+分频模块,然后再用顶层文件把它们组合在一起。
寄存器模块:
1 | module shift1(clk,D,MD,QB); |
分频模块:
记得一开始的十进制可加可减计数器设计中,我们没有用分频模块,而是把时钟模块绑到了一个按键上,然后按一次表示一个时钟,这样很麻烦,引入分频模块就很有必要了。
1 | module div( |
顶层文件:
1 | module top( |
注意:
测试子模块时,比如寄存器模块,那么写完这个模块时,就应该编译,然后写测试文件直接就测试,不要先等写完顶层模块再测试,否则系统会默认测试的是顶层文件,可能会导致没有任何输出产生的情况。
如果没有什么问题,你写顶层文件,然后保存,会出现如下的样子:
表明顶层文件和子模块联系成功,编译没有错误之后,就可以进行下一步了。顶层模块也可以不用测试,如果不写测试文件的话,可以选择 综合下面的:
然后就可以看形成的逻辑图,再比对是否哪里有问题,按照以上程序设计会生成以下的图:

移位寄存器模块如何编写测试文件,可以参考如下链接:
https://blog.csdn.net/weixin_43877139/article/details/88851235
我也写了几篇关于Veirlog的文章,感兴趣的同学可以去看看。该模块链接如下:
Verilog学习
重要:安装Mono一定要参照官方文档
一开始安装的时候走了很多的弯路,就是没看官方帮助文档。实际上当你想安装什么东西,首选就是官方文档,其次才是别人的经验把。
官方帮助文档:https://www.mono-project.com/download/stable/#download-lin
这里面介绍的很清楚:对于不同的系统也有自己的安装方法。
第一步:
1 | sudo apt-get update |
第二步:
1 | sudo apt install gnupg ca-certificates |
第三步:
根据自己的需要,可以根据官方文档中的提示,选择安装不同的类库。这种方式可能会出现下载速度过慢的情况,可以把安装源换为国内的,然后使用,具体请Goole或者百度。
我这里选择的是5.20.1.19版本,你可以自行选择下载安装的版本。
下载地址:http://download.mono-project.com/sources/mono/
第一步:
1 | sudo apt-get update |
第二步:
1 | cd /usr/local/src/ |
sudo make这一步执行之后,可能提示你缺少 cmake 这个依赖。执行
1 | sudo apt install cmake |
之后继续步骤就可以了。
这些步骤执行之后,可以输入 mono -V 查看版本信息。如下图一样便是成功了。
实际上感觉在ubuntu系统的服务器发布C#写的网页还是比较费劲的,推荐还是用Windows server系统安装IIS来发布Asp.net网站。最近我也在弄这个,有兴趣的朋友可以去看我发的相关内容。
移位寄存器的设计:
有三个模式:
左循环
右循环
加载预置的数
具体功能可以根据需要对程序做出一些修改即可
代码如下:
1 | module shift1(clk,D,MD,QB); |
测试文件
1 | module shift1_tb(); |

这里图形没有从一开始截取,而是选择能看到三个模式效果的时间段,MD=0时,一直在加载预置数,输出等于D 11110000.MD=1时,开始循环左移。MD=2时,开始循环右移。
基本的设计就是这样子,可以在它的基础上进行改进,以达到大家需要的功能,比如在shift1中的case加几个模式。D的值也可以随便赋值。
我也写了几篇关于Veirlog的文章,感兴趣的同学可以去看看。该模块链接如下:
Verilog学习
1 | module M10_updown( |
1 | module M10_updown_tb(); |
仿真图如下:

我也写了几篇关于Veirlog的文章,感兴趣的同学可以去看看。该模块链接如下:
Verilog学习
步骤:(1)找出基线条件,这种条件必须尽可能的简单
(2)不断将问题分解(或者说是缩小规模),直到符合基线条件
给定一个数组:2,4,6
需要将这些数字相加,并返回结果。使用循环很容易。
1 | public static int sum(int[] arr){ |
第一步:找出基线条件。最简单的数组:不包含任何元素或只包含元素,这样计算总和非常容易。
第二步:每次递归调用都必须离空数组更进一步。
那么如何缩小问题的规模呢?给sum传递的数组更短。
练习:
分析:这个问题基线条件比较清晰,不太清晰的点其实是递归条件,如何让数组离空数组更近一步呢?一开始我想的是,把数组截取,让数组长度每次调用都减一。其实这样想就有点偏差了,因为让数组变成空数组,其实并不是真的让数组逐渐的变为空数组,其实一直都是原来的数组,只不过每次调用的元素都是数组中的不同元素。下面的代码可能会更加帮助理解递归条件:
代码如下:
1 | /* |
分析:乍一看这个问题和4.1不太一样,但是如果数组中每个元素的值都是1的话,是不是这时候求数组的和,得到的就是列表中所包含的元素数。所以只需要把上述的代码稍做修改即可。
代码如下:
1 | /* |
分析:这个问题就比前两个深化一些了,要找出列表中的最大值,其实有很多方法。如果用递归去做,其实还是要考虑基线条件和递归条件。和前两个问题类似,递归条件还是想让传入的数组的长度原来越短,换句话说就是,想要比较的元素数越来越少。这里可以把一个数组分割成为两个,通过数组的下标做判断。左数组找出一个最大值,右数组找一个最大值,再进行比较,返回大的那个。
代码如下:
1 | public static int findMax(int[] arr,int leftIndex,int rightIndex){ |
我的测试数组为2,4,6,8
